Introducing Solar Mini : Compact yet Powerful
2024/01/25 | Written By: Eujeong Choi (Technical Writer)
The best model you’ll find under 30B
Welcome to the era of Solar, a pre-trained Large Language Model (LLM) from Upstage. In December 2023, Solar Mini made waves by reaching the pinnacle of the Open LLM Leaderboard of Hugging Face. Using notably fewer parameters, Solar Mini delivers responses comparable to GPT-3.5, but is 2.5 times faster. Let me guide you through how Solar Mini revolutionized the downsizing of LLM models without sacrificing its performance.
Looking into the model :
Why we need Smaller LLMs
Size became a pivotal factor in integrating Large Language Models (LLMs) into real-world applications. The main advantage of smaller models is their reduced computational time, which boosts responsiveness and efficiency. This translates to lower manpower requirements for optimization, as these LLMs are more straightforward to customize for specific domains and services. Additionally, their compact size enables on-device deployment, facilitating a decentralized approach that brings AI capabilities directly to the user's local device. This not only enhances accessibility but also diminishes the dependence on extensive GPU resources, paving the way for more new and affordable AI solutions.

Speed of Solar
Compact Size, Mighty Performance
Solar Mini is proof that you don't need a large size for exceptional performance. It impressively outshined competitors like Llama2, Mistral 7B, Ko-Alpaca, and KULLM in a range of benchmarks.
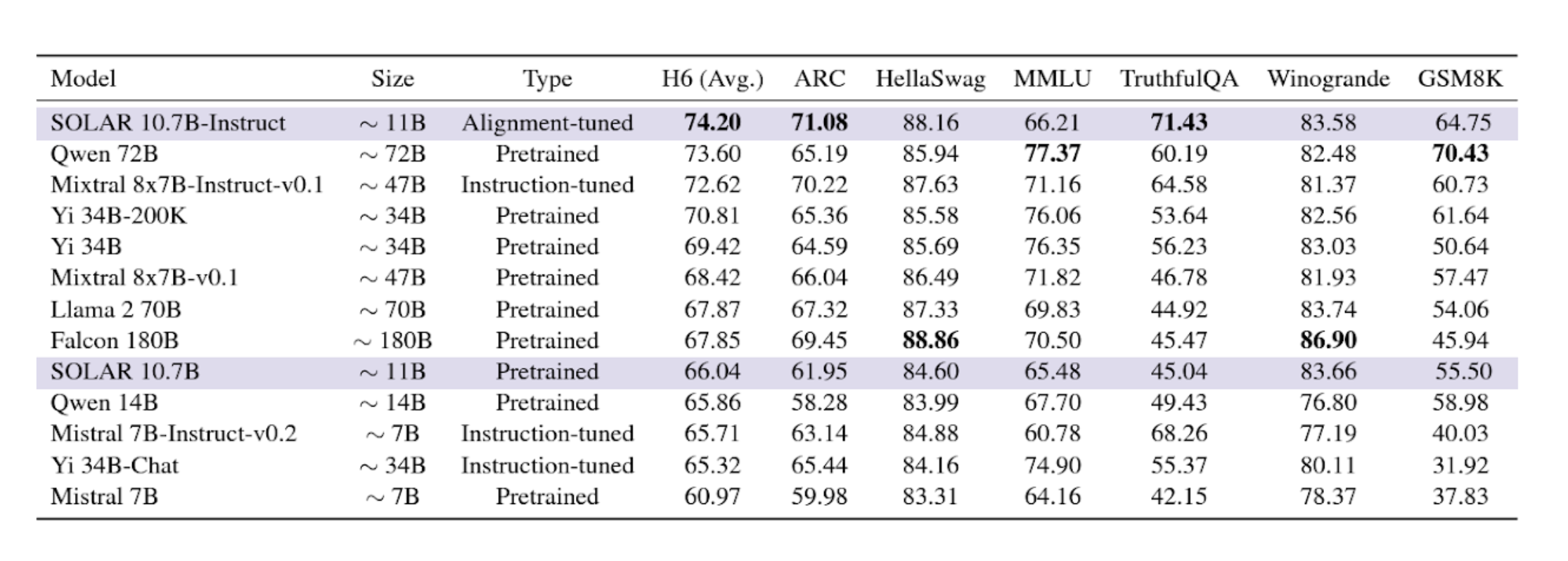
Evaluation results for Solar 10.7B and Solar 10.7B-Instruct along with other top-performing models. (Source: Solar 10.7B: Scaling Large Language Models with Simple yet Effective Depth Up-Scaling)
Building Solar Mini
Fundamentals
The foundational architecture of Solar Mini is based on a 32-layer Llama 2 structure, and is initialized with pre-trained weights from Mistral 7B, one of the best-performing models compatible with the Llama 2 architecture.
Depth Up-scaling (DUS)
How did Solar Mini Solar Mini stay compact, yet become remarkably powerful? Our scaling method ‘depth up-scaling’ (DUS) consists of depthwise scaling and continued pretraining. DUS allows for a much more straightforward and efficient enlargement of smaller models than other scaling methods such as mixture-of-experts.

Unlike Mixture of Experts (MoE), DUS doesn’t need complex changes. We don’t need additional modules or dynamism; DUS is immediately compatible with easy-to-use LLM frameworks such as HuggingFace, and is applicable to all transformer architectures. (Read paper → )
Continued Pre-training
After depth up scaling, the model performs worse than the base LLM. Therefore, a continued pretraining stage is applied to recover the performance of the scaled model.
Instruction Tuning
In this stage, the model undergoes instruction tuning specifically for Korean, where it is trained to follow instructions in a QA (Question and Answer) format.
Alignment Tuning
In this stage, the instruction-tuned model is trained to align with human or powerful AI preferences.
Use Solar with high-end components
RAG
Solar Mini especially works well with RAG systems. As LLMs get bigger, LLMs rely more on the pre-trained, parametric knowledge to answer your questions. Solar Mini effectively utilizes RAG to augment the precision and relevance of the output, thereby reinforcing its accuracy and reliability.
We have models that extract tables and figures from any document you have. Your PDF, PNG, JPG data are all covered through our OCR and Layout Analysis module. By serializing elements based on reading order and converting the output to HTML, it becomes a ready-to-go input into the LLM.
Solar Mini is publicly available under Apache 2.0 license.
For more : Read Paper / Try it on Hugging Face / Try it on Poe