(Almost) Zero Hallucination with RAG and Groundedness Check
2024/03/08 | Written By: Eujeong Choi (Technical Writer)
What is RAG, and Why Do We Need It?
What concerns you most about implementing LLMs in your business? For many, the primary worry is the unreliability of LLMs due to their propensity for hallucinations. How can we rely on LLMs to provide an adequate output when their responses often seem arbitrary?
The solution lies in RAG, short for Retrieval Augmented Generation. This approach mitigates the inherent issue of LLM hallucinations by anchoring responses with evidence from relevant documents. It guides the language model towards the specific information requested, significantly reducing the tendency to produce unfounded or irrelevant outputs. Let's explore the RAG system in detail.

A depiction of a RAG & Groundedness Check pipeline
About Hallucination Problems
Suppose you are developing an LLM for OTT services. It's plausible users might ask, "Can you recommend a good movie to watch with my friends? We're a group of four and we dig horror movies from the late '80s."
If not trained on movie-related data, a hallucination issue with an LLM is highly expected. The responses it generates could be factually incorrect, but we wouldn’t realize it before we look it up. For example, the LLM might say, “Sure! How about ‘Screaming in the Woods’ starring a famous actress from the '80s?" even though no such movie exists. This problem is rooted in the core functionality of language models, which depend on next-word prediction, opting for the most plausible word that could follow. The language model doesn’t really care if the output is true or not, it just cares what word is most likely to appear after this one.
Basic Understanding of the RAG system
How does the RAG system equip the LLM with the necessary foundation to generate grounded responses, complete with sources?
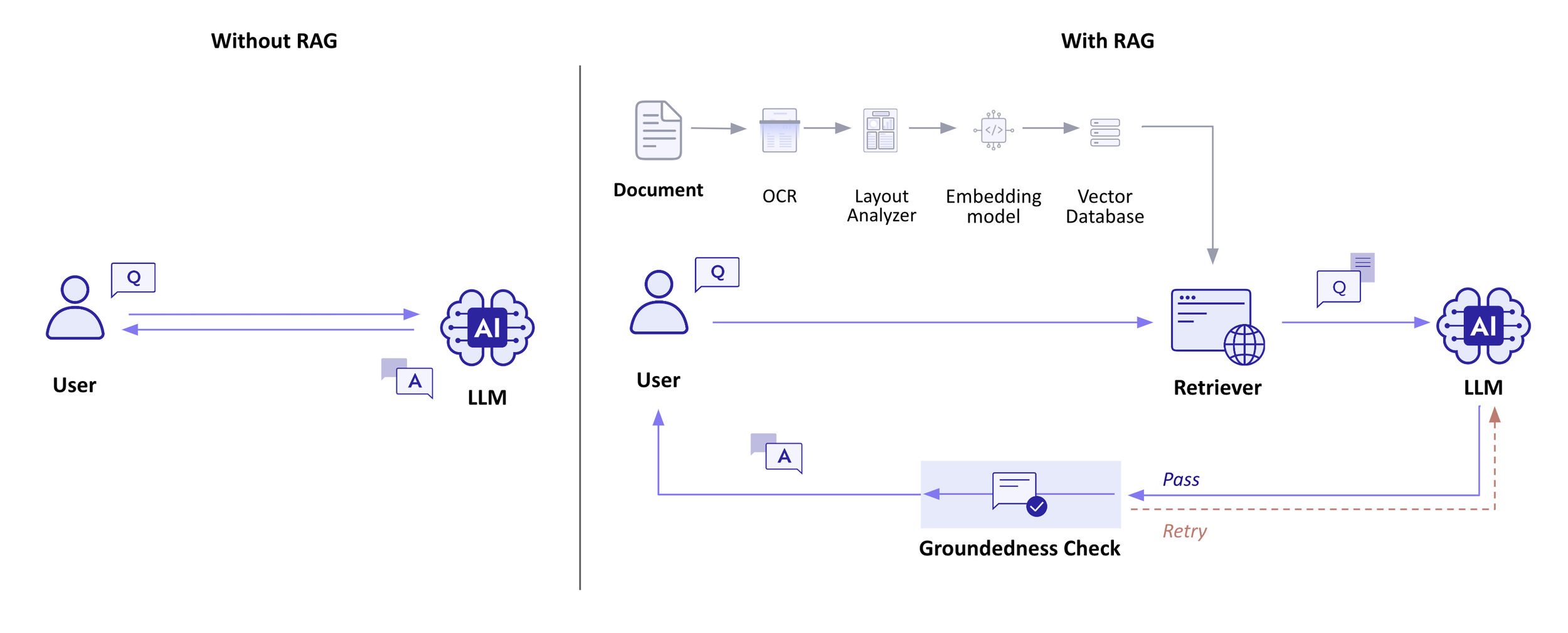
With and without RAG
The first step in RAG involves integrating your own data into an embedding model. By converting text data into vector form, we establish a vector database. This database, abundant with widespread vectorized information, prepares the ground for the retriever to source information pertinent to the user's query.
A little more about : Groundedness Check
Groundedness Check significantly bolsters the system's reliability as the final step. By validating the answer before it is delivered to the user, we guarantee the precision of the provided information. This critical step considerably lowers the chance of hallucination to nearly zero.
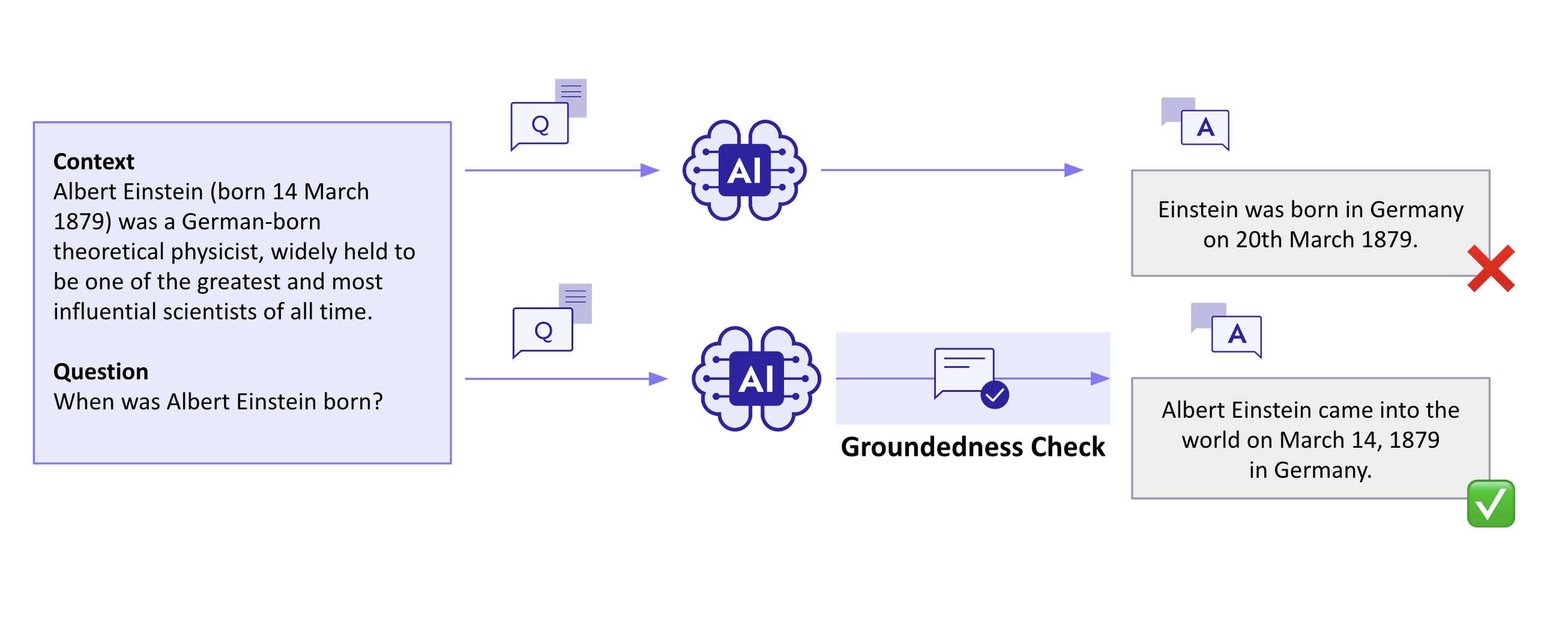
With and without Groundedness Check
While RAG significantly addresses the hallucination issue in LLMs, Groundedness Check acts as a safeguard to confirm the accuracy of the response. Reflecting on the example provided, RAG alone might not prevent an initial inaccurate response from being presented to the user as shown in the first case. However, Groundedness Check allows for the response to be redirected to the LLM, offering a chance for correction.
This process of Groundedness Check meticulously checks if the output aligns with the content from the reference document. By ensuring the answer is consistent with the retrieved data, it verifies that the model's output is firmly anchored in the provided context, thereby eliminating scenarios where the response is unmoored from the given information.
Case Study
This section highlights how RAG has facilitated the deployment of LLM in real-world services.
Extra Large Dataset? Got you covered.
Upstage has demonstrated remarkable outcomes with RAG alongside LLM, notably with the Korean Institute of Press. Our client aimed to enhance their expansive news big data system, faced with the challenge of a voluminous dataset. They needed to access information from over 30 years of accumulated news data, amounting to approximately 80,000,000 press documents.
The objective was to navigate this vast database without significant time delays. This was achieved through the implementation of a hybrid search technique, which merges dense and sparse search methods to balance speed with precision. The tangible business impact observed from this endeavor was the capability to swiftly retrieve pertinent references from the massive collection of 80 million documents, ensuring timely and relevant service delivery.
Need RAG and Fine-tuning at once? Got you covered.
The second case involved collaboration with an entertainment firm aiming to develop a conversational agent characterized by a distinct persona. The challenge was to create an agent capable of maintaining a relationship with users, necessitating the ability to remember facts about itself and to recall previous dialogues with users. Additionally, the language model required robust safeguards to counter adversarial attacks and jailbreaking attempts, which are common challenges for human-like conversational agents.
To construct a persona, sustain user relationships, and implement safeguards for the LLM, we combined RAG with fine-tuning to achieve the desired service level. We developed a system that segregates memory into short-term memory, which retains the context of conversations with users, and long-term memory, which preserves the agent's persona. This innovative approach of integrating RAG with fine-tuning resulted in the creation of a complex yet human-like agent, showcasing the effectiveness of this strategy in producing advanced conversational agents.
How do we prepare the data? Layout Analysis
Creating a trustworthy dataset for retrieving reference texts is crucial, especially to ensure that answers are accurately grounded in your data. The deep learning mantra "Garbage in, garbage out" emphasizes the importance of data quality provided to the language models. To make your documents ready for LLM, our Layout Analysis is an invaluable tool.
Here is an example of a hypothetical random document about Upstage.

If you have a PDF format document looking just like this, it would be an unstructured document. How can you then structure your data for the vector database? Is OCR (Optical Character Recognition) sufficient?

OCR alone is insufficient! Recognizing the layout of your document is essential for the LLM to accurately interpret your data. Simply conducting OCR misses the implicit information communicated through the document's layout, like tables and formatting. Therefore, a holistic approach that encompasses layout analysis is crucial to thoroughly prepare your data for LLM integration.
Summary
At the end of the day, it all comes down to this. RAG can ground your answers with data, Groundedness Check can double check your answers, and layout analysis will get this data ready. With these tools and components, Upstage’s LLM Solar can be of use in your business right away.