
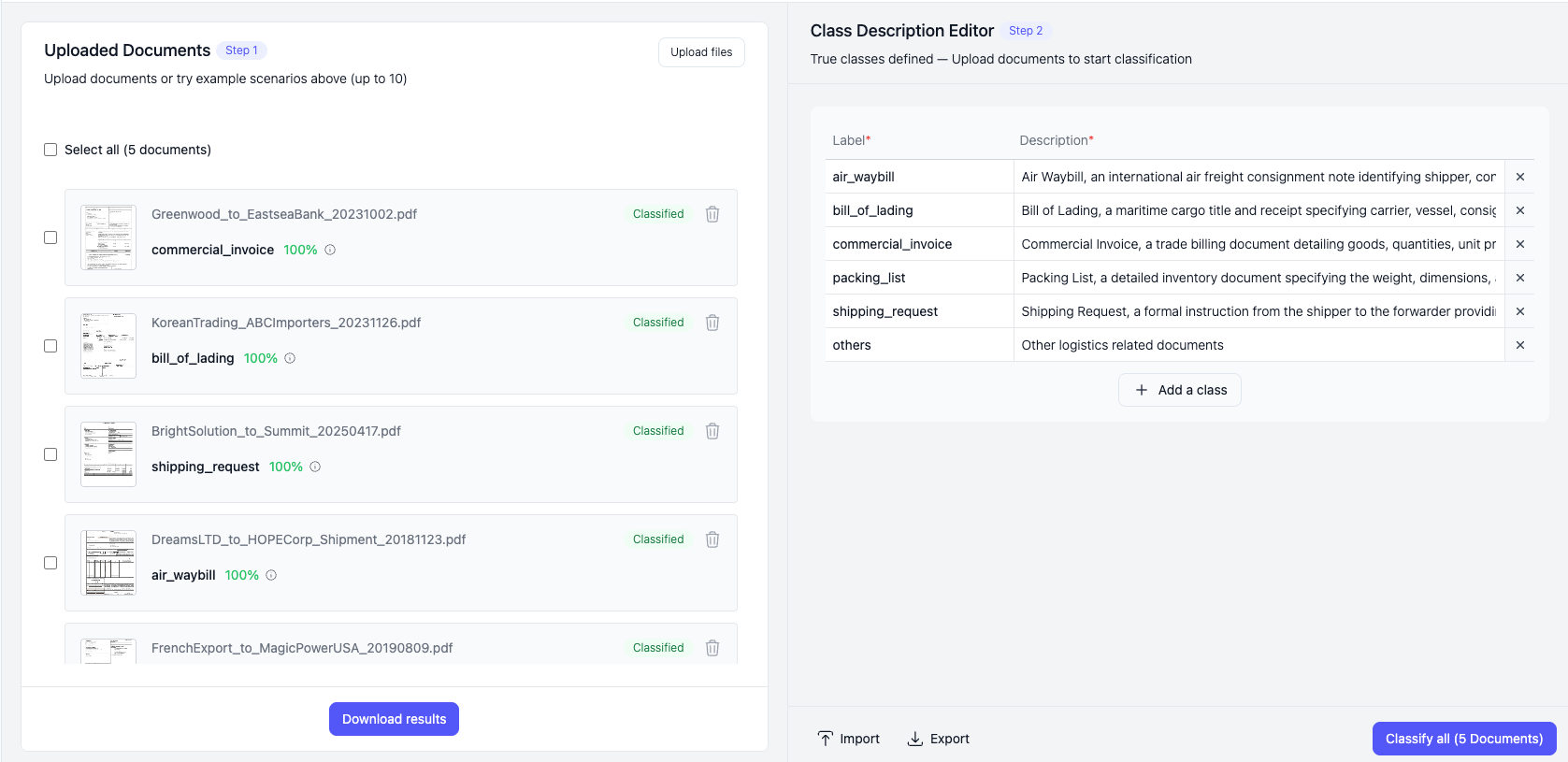
.png)
Enterprise document workflows begin with identifying what kind of document has been received. Invoices, receipts, statements, tax forms, ID documents, and various business or operational forms arrive as PDFs, scanned images, mobile captures, or legacy exports. Document Classify provides a consistent way to determine the document type across these formats, establishing a reliable entry point for downstream parsing, extraction, and automation.
Limitations of fixed-class classification systems
Traditional document classifiers rely on a fixed set of categories defined during training. They work only as long as incoming documents resemble the templates they were trained on. When businesses onboard new partners, encounter regional format variations, or adopt new operational documents, these models begin to break—requiring data collection, re-labeling, and costly retraining.
Document Classify removes this limitation entirely. Instead of relying on pre-trained categories, it classifies documents using a user-defined taxonomy, allowing organizations to expand their document types instantly by updating descriptions rather than updating the model itself.
A universal, taxonomy-driven approach
Document Classify supports a wide range of structured, semi-structured, and unstructured document types. The model analyzes semantic content together with layout and visual patterns, allowing it to classify documents reliably across varying structures and capture conditions.
Common examples include:
- Financial documents: invoices, statements, payslips, tax forms
- Insurance & healthcare documents: EOBs, claims, member ID cards, summaries
- Business documents: contracts, letters, notices
- Identity documents: licenses, passports, membership IDs
- Transactions: POS receipts, mobile-captured receipts
- Reports & certificates: inspection reports, manufacturing certificates
Because the system is taxonomy-driven, organizations can scale their document sets without modifying the model.
A universal, taxonomy-driven approach
Document Classify combines semantic understanding with layout and visual cues to classify structured, semi-structured, and unstructured documents. Because the model selects the best match from a taxonomy you provide, it can scale to any number of document types—whether you define five categories or five hundred.
Zero-shot expansion without model updates
Teams define document types using simple descriptions:
[
{ "name": "invoice", "description": "Commercial billing documents with amounts and vendor details." },
{ "name": "receipt", "description": "Transaction-level purchase receipts." },
{ "name": "tax_form", "description": "Government-issued tax reporting forms." },
{ "name": "contract", "description": "Documents outlining agreements or terms." }
]
The model reads these descriptions at a semantic level and applies them consistently across documents. As workflows expand or new form types appear, only the taxonomy needs to be updated—no fine-tuning or redeployment required.
Robust across formats and capture conditions
Documents often arrive in inconsistent formats or imperfect quality. Document Classify maintains stable performance across:
- digital and scanned PDFs
- JPEG/PNG/TIFF images
- multi-page scans
- mobile captures
- legacy system exports
Because the model does not rely on templates or complete OCR output, it performs reliably even when resolution, alignment, or structure varies.
Insurance documents are a representative example of this complexity. They include many visually similar forms—such as invoices, statements, claim summaries, and receipts—making precise semantic distinction particularly important in real workflows. In internal evaluations across English and Korean insurance documents, the model achieved 92.1% accuracy when the taxonomy fully reflected the document types used in the workflow.
A dependable foundation for downstream workflows
Reliable classification improves every stage of the document intelligence stack:
- Information Extract loads the correct schema for structured extraction
- Workflow engines and AI agents can route, validate, and process documents with higher confidence
Document Classify establishes a universal, semantic first layer for modern automation and document understanding workflows.
Get started today — free during the beta period
Document Classify is now available in beta and can be used free of charge during the beta period.
Upload your documents, define your taxonomy, and evaluate how the model fits into your workflows—no templates, training, or setup required.
Resources
- Developer Documentation: API specification and integration examples
- Playground Demo: Upload documents and try Document Classify instantly



