

Document Classifyのご紹介:あらゆる文書を意味に基づいて分類
企業の文書ワークフローは、まず「これはどんな文書か」を把握することから始まります。
請求書、領収書、明細書、税務書類、身分証明書等の業務文書が、PDFやスキャン画像、スマホ撮影、レガシーシステムのエクスポートなど、さまざまな形式で日々扱われているでしょう。
Document Classify は、こうした文書の種類を事前に判定することで、下流の解析や自動化処理を安定して実行できるようにします。
既存の文書分類システムの限界
従来の文書分類モデルは、学習時に定義された固定のカテゴリに基づいて動作します。
そのため、受け取る文書が学習時のテンプレートやパターンと似ている場合にのみ、正しく機能します。
しかし、新しい取引先の追加や地域ごとのフォーマットの違い、これまでにない書類形式が導入されると、モデルは柔軟に対応できません。その結果、追加のデータ収集や再ラベル付け、再学習といった手間が発生してしまいます。
Document Classifyは、この制約を根本から解消します。事前学習のカテゴリに頼らず、ユーザーが定義した分類体系に基づいて文書を分類します。そのため、モデル自体を更新することなく、分類の説明を追加・変更するだけで、新しい文書タイプを即座に拡張することが可能です。
あらゆる文書に対応する分類アプローチ
Document Classifyは、構造化文書、半構造化文書、非構造化文書など、幅広い文書タイプに対応しています。モデルは文書の意味的内容に加え、レイアウトや視覚的パターンも分析するため、構造や撮影条件が異なる文書でも安定して分類できます。
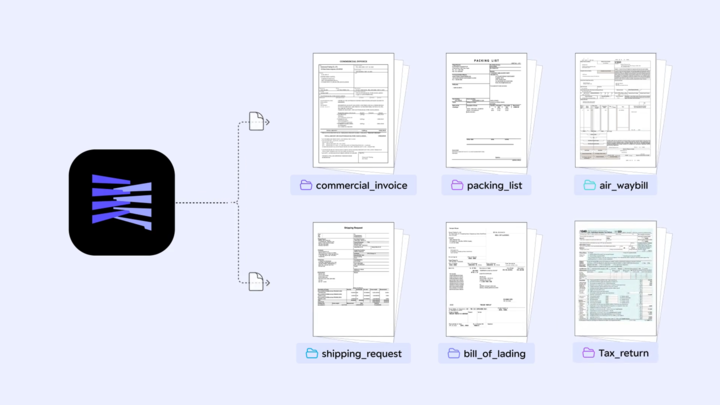
例:
- 請求書、明細書、給与明細、税務書類
- EOB、保険請求、会員IDカード、サマリー
- 契約書、通知書、書簡
- 運転免許証、パスポート、会員ID
- POSレシート、スマホ撮影レシート
- 検査報告書、製造証明書
分類体系に基づくシステムのため、企業はモデルを変更する必要なく、文書セットを簡単に拡張できます。ユーザーが定義した分類体系から最適な分類を選択するため、カテゴリが5種類でも500種類でも、文書タイプの数に応じて柔軟に対応可能です。
モデルの更新なしで文書タイプを追加
企業は文書タイプを、簡単な説明文で定義するだけです。
[
{ "name": "invoice", "description": "Commercial billing documents with amounts and vendor details." },
{ "name": "receipt", "description": "Transaction-level purchase receipts." },
{ "name": "tax_form", "description": "Government-issued tax reporting forms." },
{ "name": "contract", "description": "Documents outlining agreements or terms." }
]
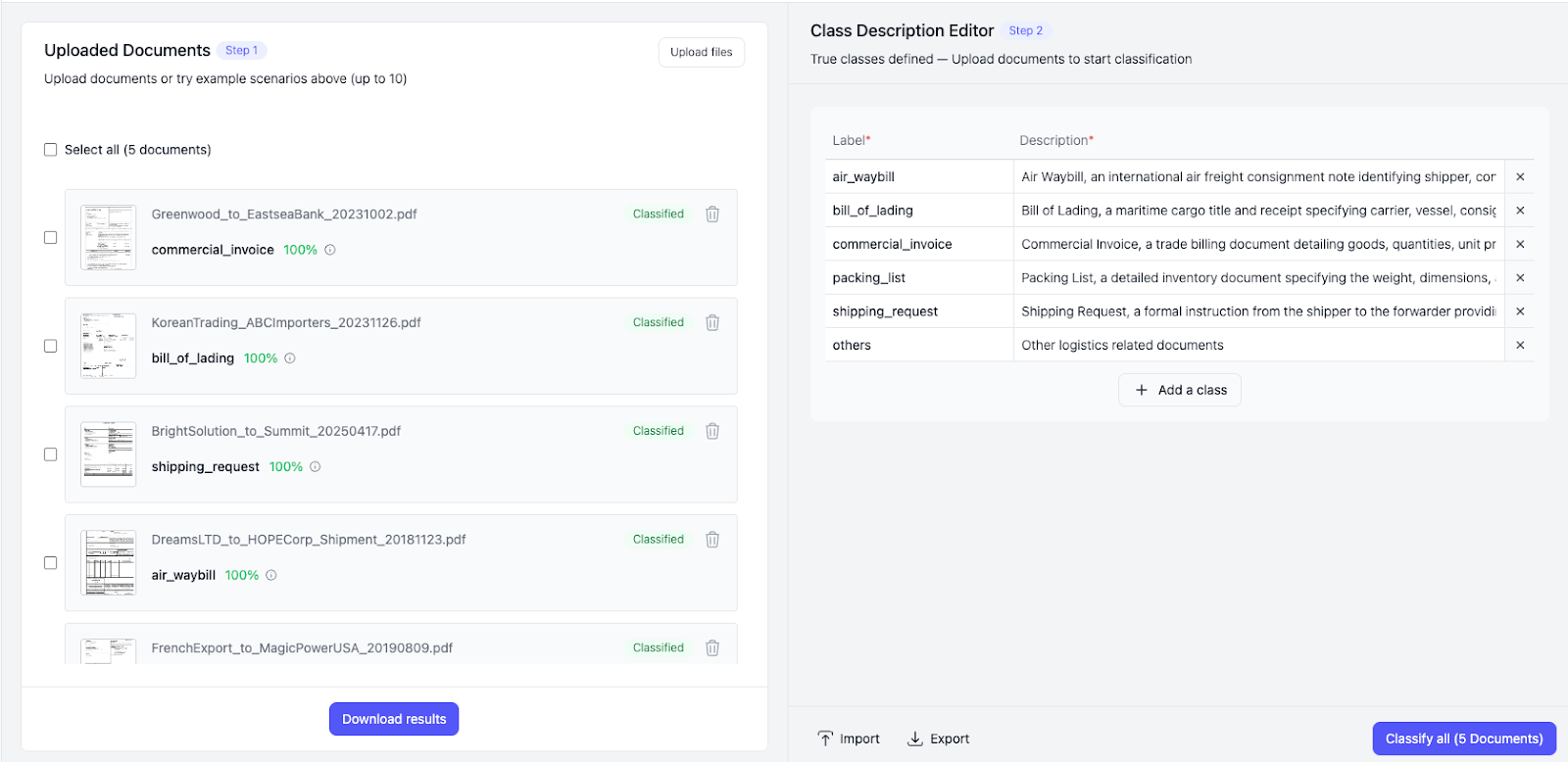
モデルはこれらの説明を意味として理解し、文書全体に一貫して適用します。
ワークフローが拡張されたり、新しい文書タイプが追加された場合でも、更新が必要なのは分類の説明だけで、モデル自体の再学習や再展開は不要です。
形式や取得条件に左右されない高いロバストネス
文書は形式がバラバラだったり、品質が不完全な状態で届くことがあります。Document Classifyは、以下のような状況でも安定した分類性能を発揮します。
- デジタルおよびスキャンPDF
- JPEG/PNG/TIFF画像
- 複数ページにわたるスキャン文書
- モバイルで撮影された文書
- レガシーシステムからの出力
モデルはテンプレートや完全なOCR出力に依存しないため、解像度や傾き、文書構造が異なっても安定して分類できます。
保険関連文書は、このような複雑さの代表例です。請求書、明細書、請求サマリー、レシートなど、見た目が似た文書が多く含まれるため、実務では正確な意味の区別が非常に重要です。内部評価では、英語・韓国語の保険文書を対象に、ワークフローで使用される文書タイプを完全に反映した分類体系を用いた場合、モデルは92.1%の精度を達成しました。
下流ワークフローの信頼できる基盤
安定した文書分類は、「文書のデジタル化+自動処理」の各ステージをより効率的にします。
- Information Extract は、構造化データを抽出するために正しいスキーマを自動で読み込みます。
- ワークフローエンジンやAIエージェント は、文書を高精度で振り分け、検証し、処理できます。
- Document Classify は、モダンな自動化や文書理解ワークフローのための、普遍的で意味に基づいた基盤レイヤーを提供します。
今日から始められます — ベータ期間中は無料
Document Classifyは現在ベータ版として提供中で、ベータ期間中は無料でご利用いただけます。
文書をアップロードし、分類体系を定義するだけで、モデルがワークフローにどのように適合するかをすぐに評価できます。テンプレートや学習、設定は不要です。
リソース
- 開発者向けドキュメント:API仕様や統合例
- Playgroundデモ:文書をアップロードして、すぐにDocument Classifyを体験可能
![[Video] Upstage Studio デモ:複雑な日本語書類も数秒でAIエージェント化 | 保険・契約書・請求書処理を自動化](https://cdn.prod.website-files.com/6743d5190bb2b52f38e99ecd/6a62cfae0d781c69e28a672c_cover%20(3).png)

![保険毎日新聞:保険AI実装のリアル[Vol.4] AI-OCRから生成AIへ](https://cdn.prod.website-files.com/6743d5190bb2b52f38e99ecd/6a50b1c9d1db355f7740faf2_Upstagexfuriosa_16_9.png)

