
.png)
Upstage は、Document Parse に新しい処理モード「Document Parse Enhanced」を追加しました。これは、従来の標準的なパースに加えて、文書内の視覚的な要素も直接理解できるようにしたモードです。これにより、これまでテキストベースの手法では安定して扱えなかった複雑なテーブルやチェックボックス、チャート、図表も、高い精度で抽出できるようになります。
複雑な文書要素にも対応できる高い処理性能
多くの文書解析システムは、構造化されたテキストの処理を前提としています。そのため、明確なフォーマットを持たず、見た目の構造に頼っている文書では、うまく扱えないケースがあります。
しかし、Document Parse Enhanced mode は VLM(Vision Language Models)を活用することで、これらの制約を取り除き、以下のような要素を正確に理解します:
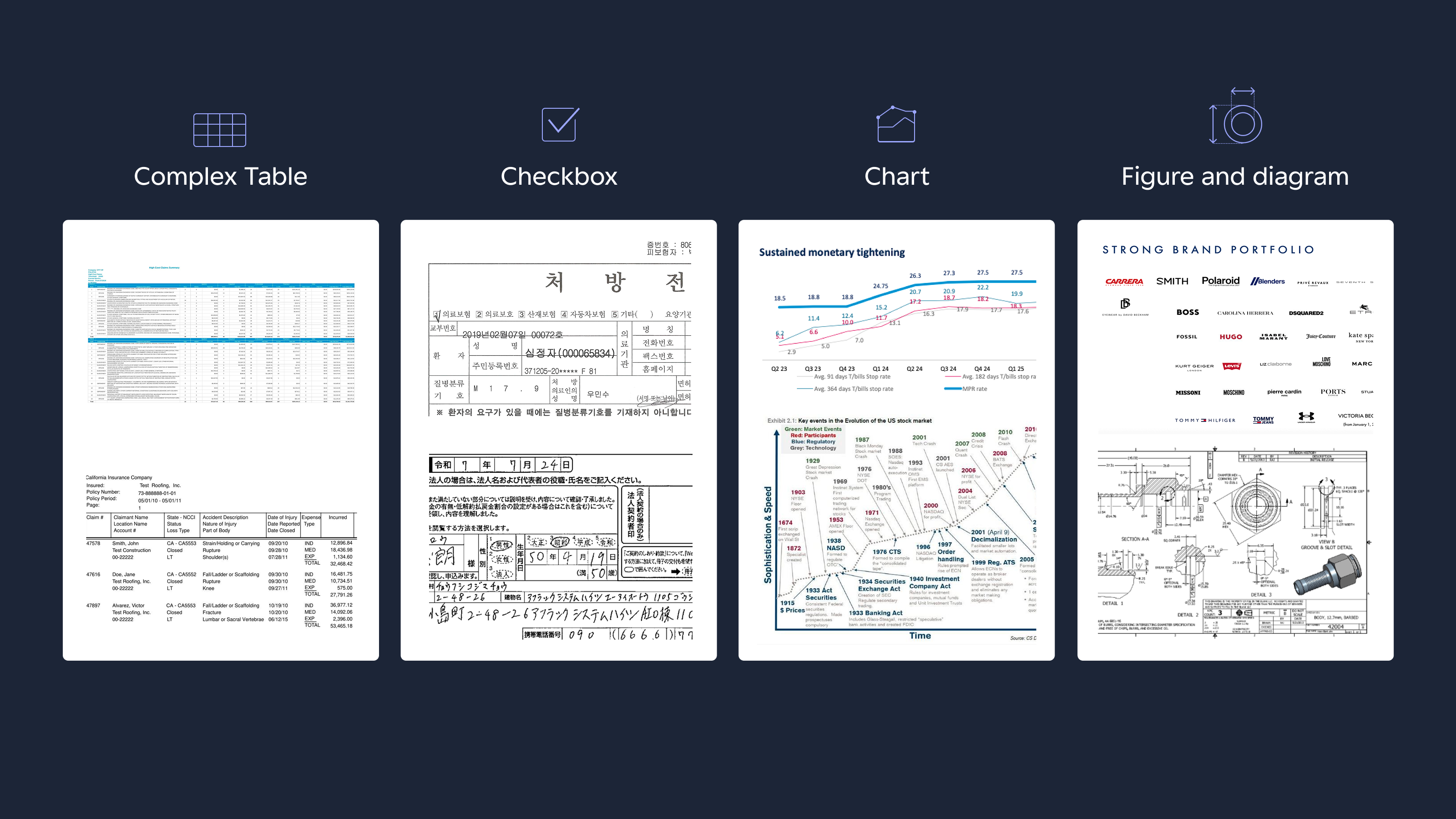
- 複雑なテーブル — 複数行セル、罫線のないテーブル、複数ページにまたがるテーブル等
- チャート — 構造化データおよび自然言語による説明へ変換
- 画像および図表 — 下流のシステムで利用しやすい、簡潔な要約に変換
- チェックボックス — チェック済み/未チェックの状態を含めて確実に検出
これらの機能は Document Parse の一部として提供されており、不規則で視覚的に複雑な文書でも、機械処理しやすい形で扱えるようになります。複雑なテーブルやチャートの解析例は、Document Parse Playground で確認できます。
Document Parse Enhanced mode の仕組み
Document Parse Enhanced mode は、もともと Document Parse が備えている高精度な OCR と信頼性の高いレイアウト理解を土台に、Vision Language Model を組み合わせることで、より複雑な視覚要素にも対応できるようになっています。
これにより Enhanced mode は、文書全体のレイアウトを踏まえて視覚要素同士の関係性を把握でき、各要素を個別に切り離して処理する必要がなくなります。
その結果、システムは次のことが可能になります:
- ページをまたぐ複雑で罫線のないテーブルを認識
- チャートを構造化された数値データと説明文に変換
- 画像や図表を要約し、LLM や下流システムが意味を理解できるようにする
- チェックボックスを検出し、チェック済み/未チェックの状態を正確に判別
パフォーマンスベンチマーク:文書ワークフローで重要な精度
以下の表は、Upstage の内部ベンチマーク dpp-bench-v1.4.0 におけるパフォーマンスをまとめたものです。
Document Parse Enhanced mode は、1ページ単位の精度だけを追求するのではなく、文書全体を通した構造の正確さ、一貫した結果、そして実運用で問題のない処理時間を重視して設計されています。これは、文書処理を中心とするワークフローで特に重要なポイントです。
1. 複雑なテーブル構造の認識
複雑なテーブルは、企業文書で最もよく使われる要素の一つであると同時に、処理が難しい要素でもあります。多くの場合、複数ページにまたがっていたり、罫線がなかったりと、厳密な構造ではなく見た目の並びに依存しているケースも多くあります。

テーブルのベンチマークにおいて、Enhanced mode は標準的なパース手法と比べて明確な改善を示しており、本番環境でも実用的な処理時間を維持しています。
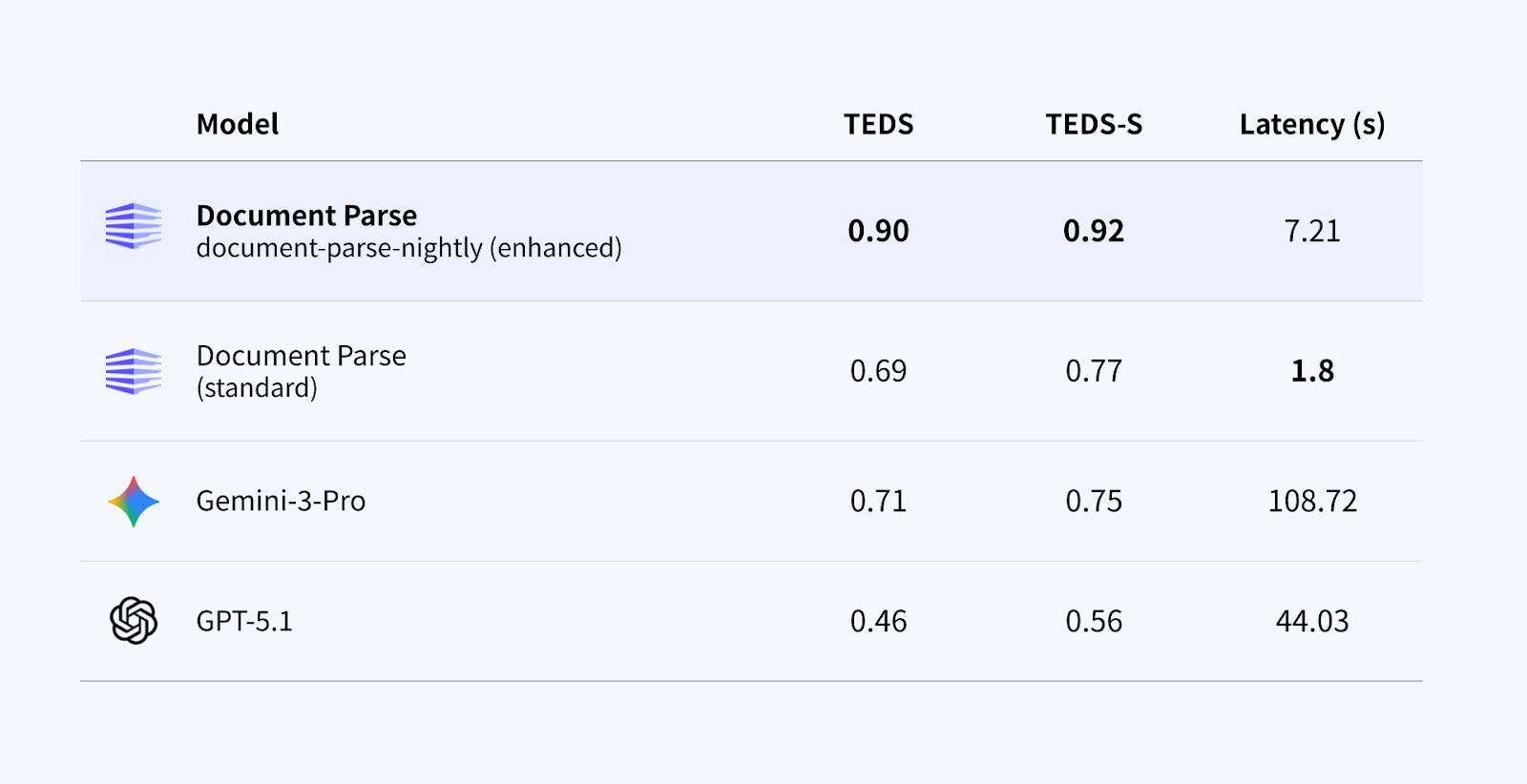
特に以下の点で改善が見られます:
- テーブル構造精度(TEDS-S)が標準モードより大幅に向上
- 汎用的なマルチモーダルモデルとは異なり、大規模文書処理においても実用的な処理時間を維持
2. 複数ページにまたがるテーブルの再構築

複数ページにまたがるテーブルでは、単純に精度が高いだけでは十分とは言えません。重要なのは、処理時間のボトルネックを生むことなく、大量の文書を扱う環境でも確実にテーブルを統合できるかどうかです。
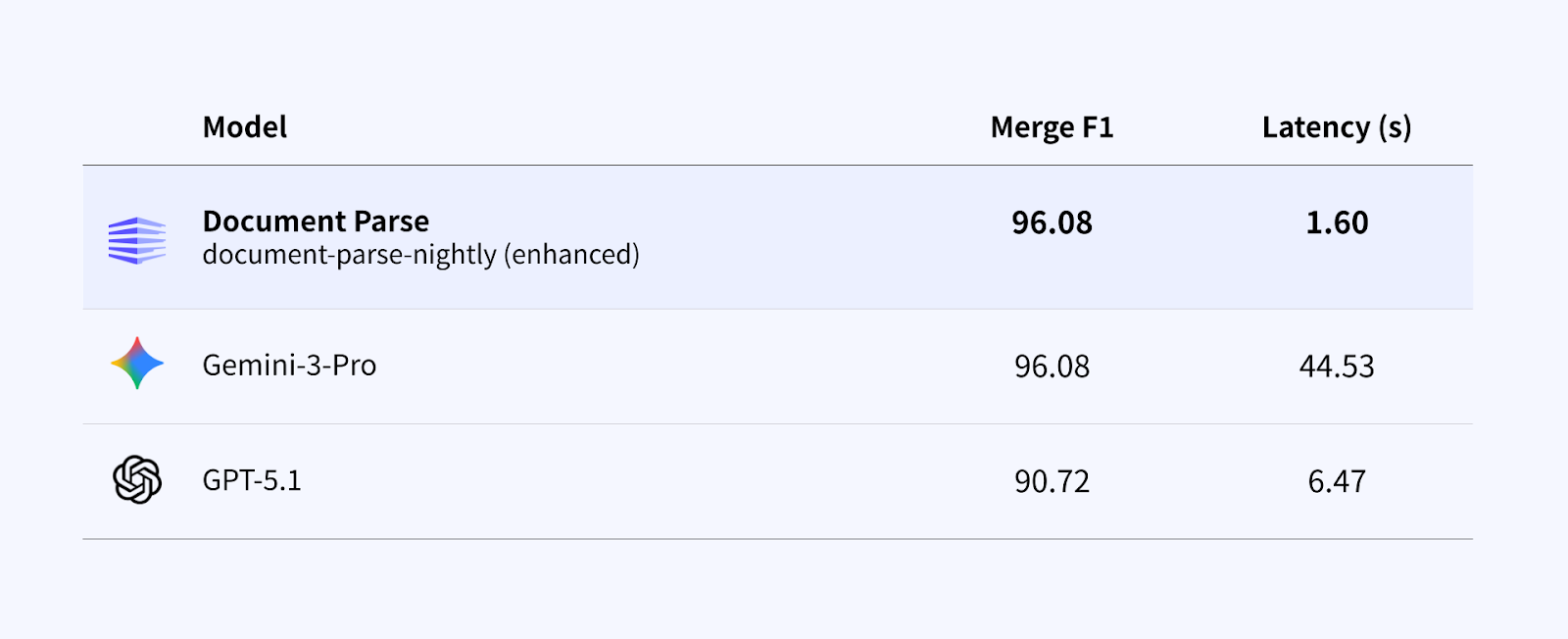
複数のモデルが高い統合精度を示す中で、Document Parse Enhanced mode は、より低い処理時間で同等の結果を提供します。これにより、数百から数千ページを継続的に処理する文書ワークフローに適しています。
3. チャートおよび画像の理解

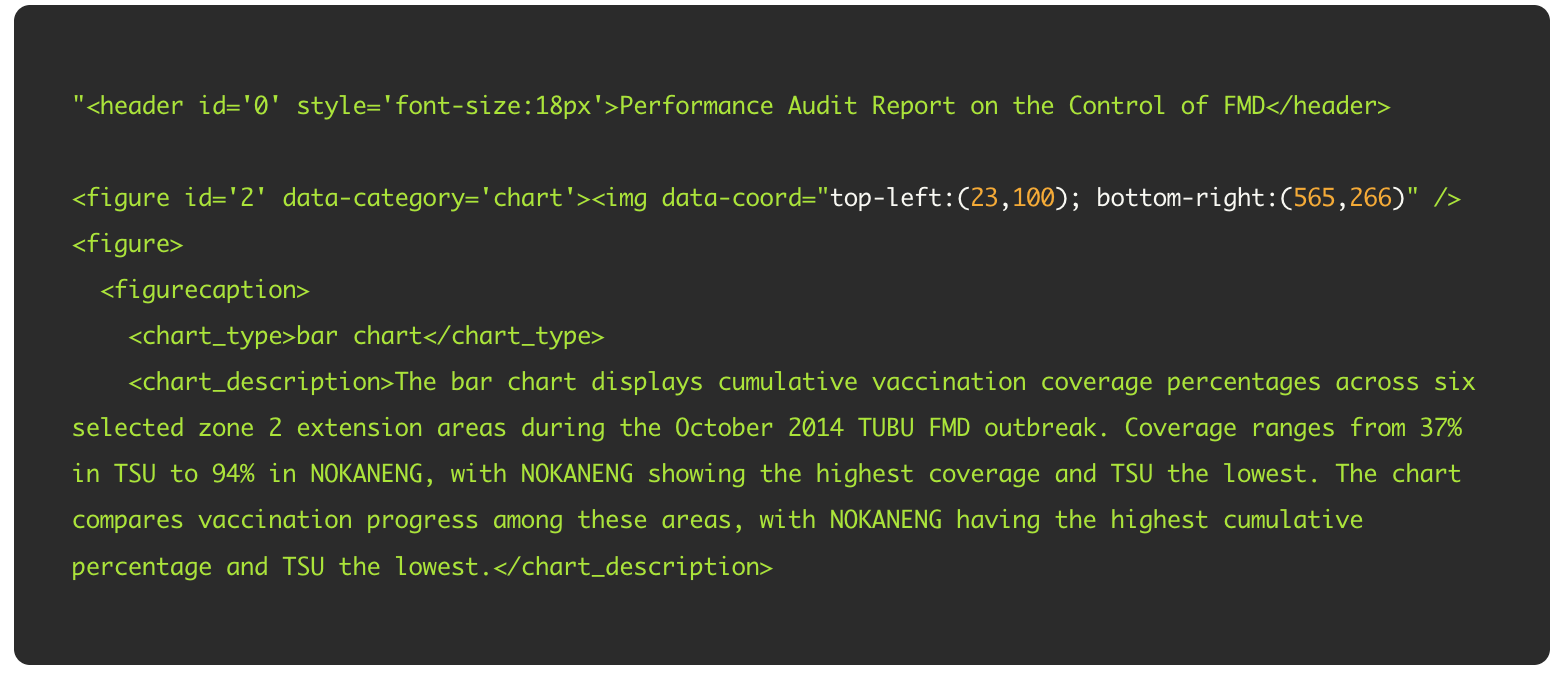
Document Parse Enhanced mode は、生の数値を抽出するだけでなく、下流の自動化で実際に使える形にすることを重視しています。
Enhanced mode は、構造化された形式での出力に加え、傾向や関係性、文脈を分かりやすくまとめた自然言語の説明も生成します。
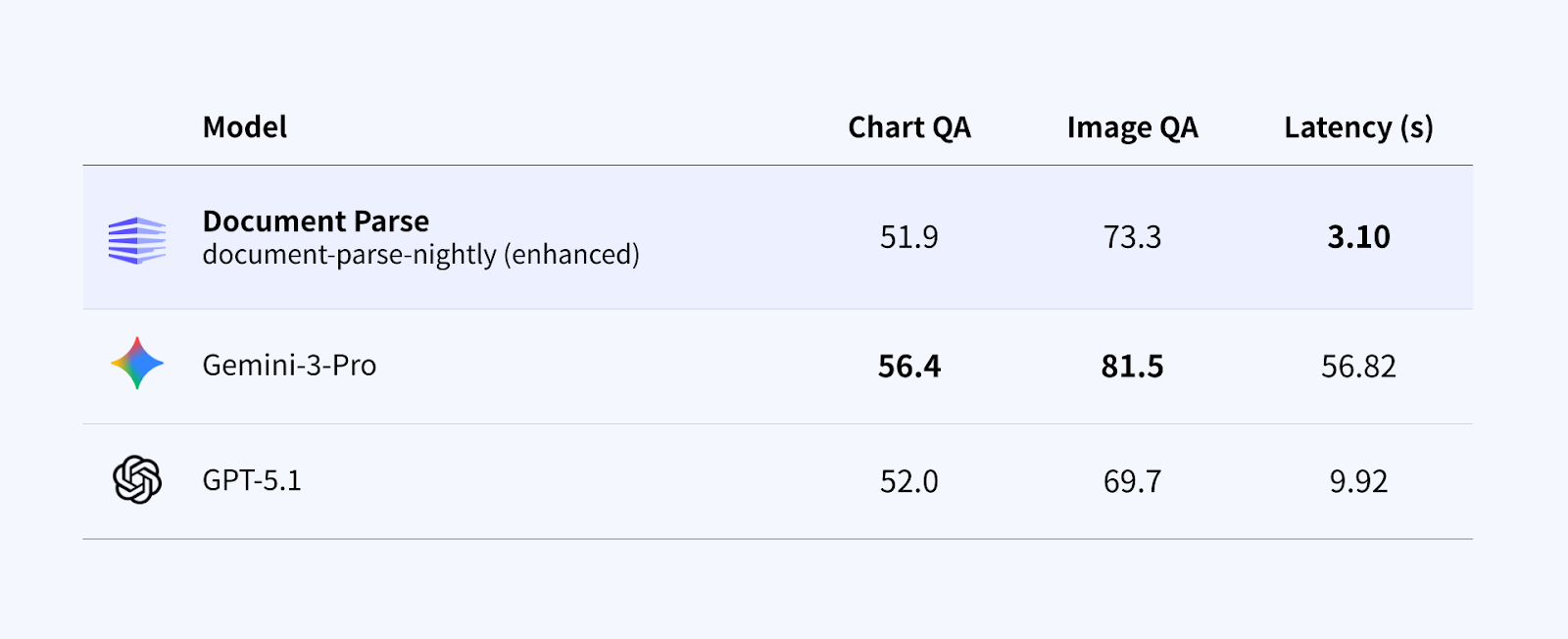
構造化出力と説明文を同時に生成できることで、視覚要素は検索・要約・推論の対象となり、数値スコアだけでは捉えきれない価値が生まれます。
チャートおよび画像のスコアは、まず各モデルでチャートや画像を含むページを処理し、その結果を GPT-4.1 に入力してタスク固有の質問で性能を評価することで算出されています。
表が示すように、Enhanced mode は最新の VLM ベースモデルと同等の理解性能を達成し、処理時間を大幅に抑えています。
4. チェックボックス認識
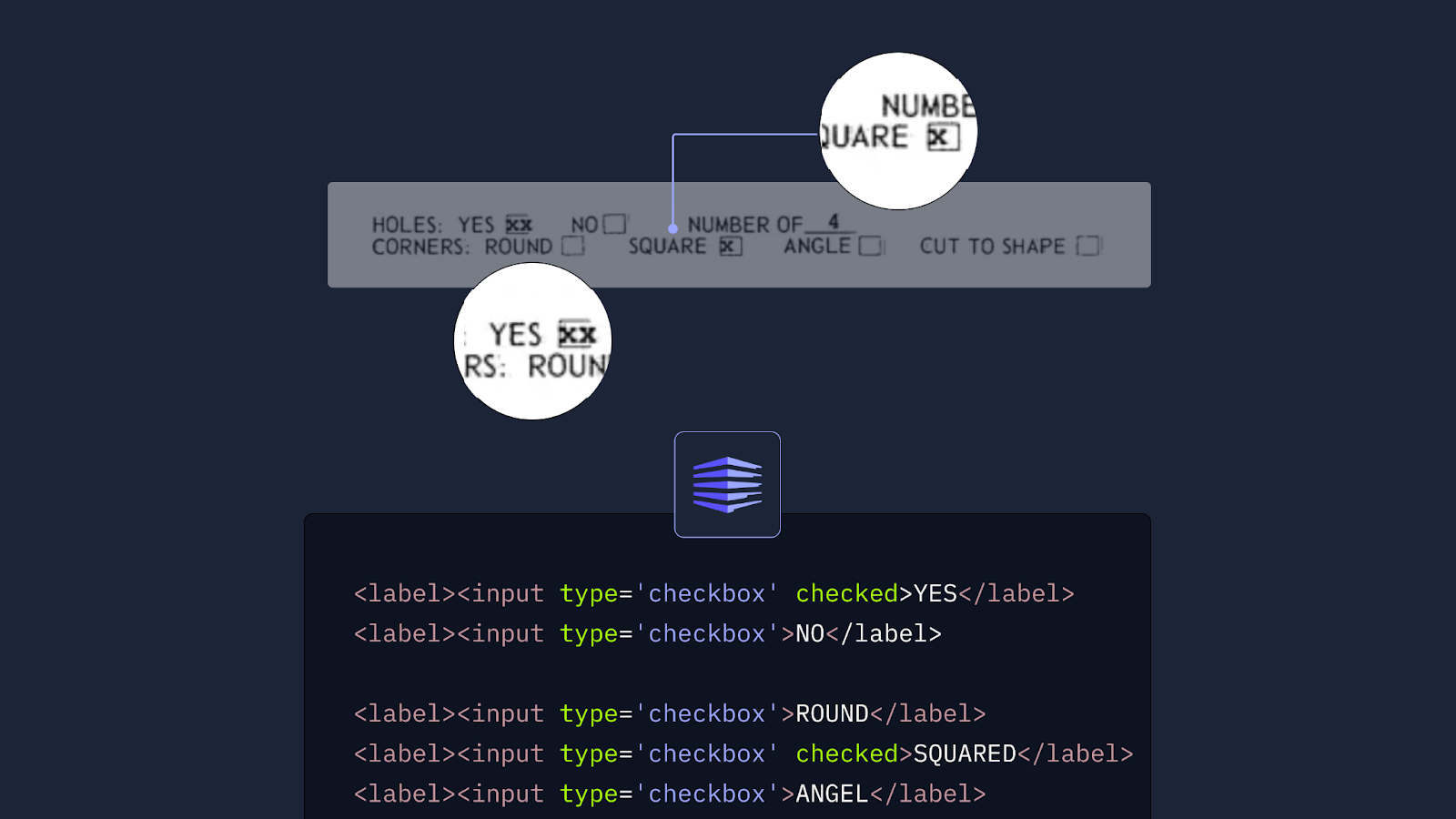
チェックボックスは小さな視覚要素ですが、多くのフォームやアプリケーションにおいて重要です。
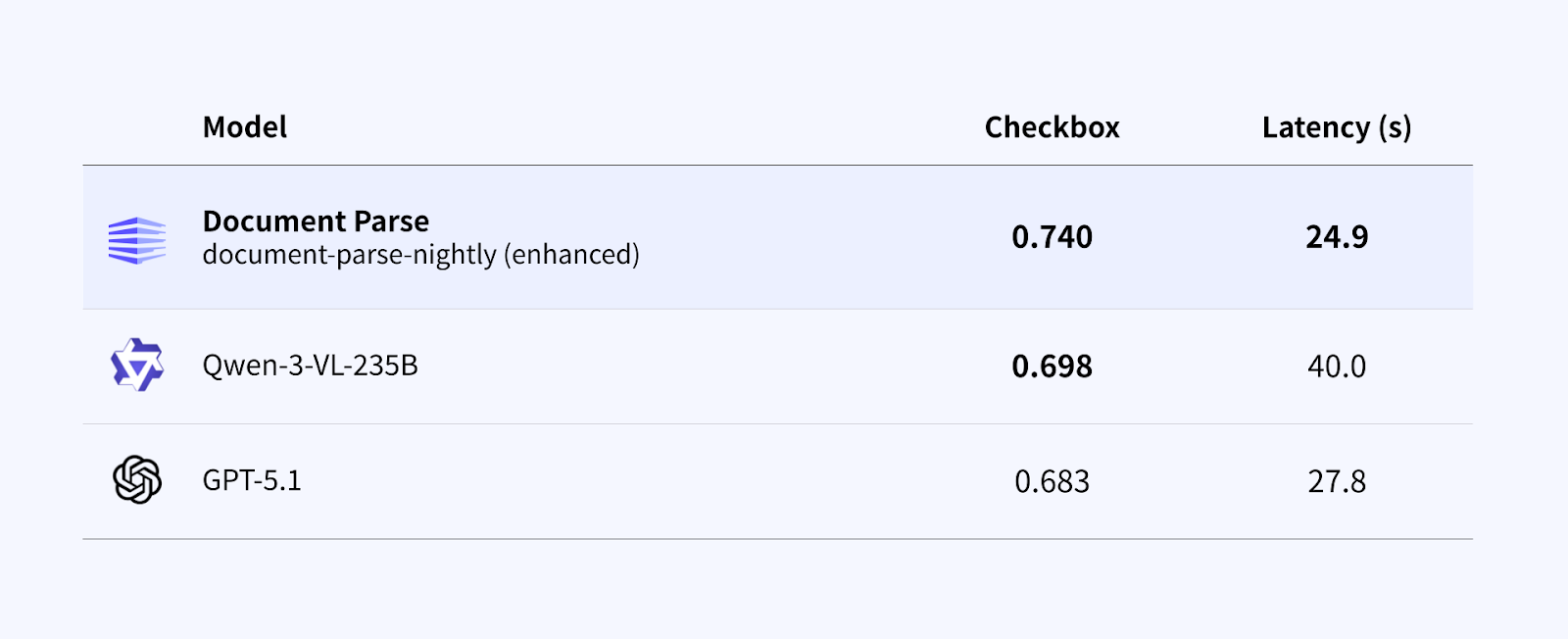
チェックボックス認識はまだ進化途中の機能ですが、Enhanced mode はすでに汎用的なマルチモーダルモデルと比べて高い精度を示しています。現在は、密集した複雑なレイアウトへの対応を中心に、継続的な改善を進めています。
ワークフローへの Enhanced mode の簡単な適用
Document Parse は、精度・処理速度・コストのバランスに合わせて選べる 3 つの処理モードを提供しています。
- Standard mode (mode=standard) – 一般的な文書解析タスク向け
- Enhanced mode (mode=enhanced) – 複雑なテーブル、チャート、図表、高密度な視覚構造を含む文書向け
- Auto mode (mode=auto) – 各ページを自動解析し、複雑さに応じて Standard またはEnhanced mode に振り分けることで、精度を最大化しつつコストを最適化
例:Enhanced mode の呼び出し

ベータ期間中、Enhanced mode は document-parse-nightly モデル経由で利用可能です。
次世代ドキュメントワークフローを形作る
Document Parse Enhanced mode は、特に複雑なテーブル、チャート、画像が処理を遅らせがちなワークフローにおいて、自動化できる範囲を大きく広げます。今後さらに多様な文書タイプやレイアウトへの対応を進めることで、既存の作業方法を変えることなく、文書駆動型ワークフローをより簡単で信頼性の高いものにすることを目指しています。
ご自身がお持ちの文書にこれらの結果がどのように適用されるかを確認したい場合は、Playground で Enhanced mode をお試しください。
今後の展開
Document Parse Enhanced mode はテーブル、チャート、画像、チェックボックスといった複雑な視覚要素を含む文書を、実際のワークフローでより適切に扱うことに重点を置いています。これらの領域は、ユーザーから最も要望の多かった分野であり、本リリースにより、こうした複雑な文書レイアウトを安定して理解・処理できる基盤を整えます。
この基盤をもとに、現在以下のような追加課題への対応も積極的に進めています:
- 手書き文字認識
- 印鑑および署名の検出
- フォントスタイルの識別
- 低品質スキャン文書への対応
これらの改善は、準備が整い次第、今後のプロダクトアップデートを通じて段階的に提供される予定です。
詳細はこちら
- Document Parse documentation
- Enhanced mode integration guide
- Information Extract for structured field-level extraction
![[Video] Upstage Studio デモ:複雑な日本語書類も数秒でAIエージェント化 | 保険・契約書・請求書処理を自動化](https://cdn.prod.website-files.com/6743d5190bb2b52f38e99ecd/6a62cfae0d781c69e28a672c_cover%20(3).png)

![保険毎日新聞:保険AI実装のリアル[Vol.4] AI-OCRから生成AIへ](https://cdn.prod.website-files.com/6743d5190bb2b52f38e99ecd/6a50b1c9d1db355f7740faf2_Upstagexfuriosa_16_9.png)

